
KLING AI has frequently appeared in major domestic and foreign technology media in the past six months and has become synonymous with a sense of technology and creativity. It represents the cutting-edge exploration of the Kuaishou AI team in the field of video generation.
As the world’s first large model for generating real-image-level videos that can be publicly experienced, KLING was officially released and launched on June 6, 2024. In just over half a year, Koling has completed dozens of iterations of upgrades to its functions and effects, and has always been firmly in the top echelon of the global video generation field, continuing to lead the industry in improving results. At the same time, it has also successively launched a number of rich and practical control and editing functions, providing a broad creative space for creative professionals around the world, fully inspiring and showcasing their inspiration.
Unlike the “Kling AI Platform” which has a wide industry influence in the field of video generation, the Kling team and its research work have always maintained a low-key and mysterious attitude. However, the technological breakthroughs and innovative thinking behind it have attracted the interest of many followers.
Recently, the Kling team has made public a number of research results, revealing their insights and cutting-edge explorations in the field of video generation. This is not only a way to give back to the academic community and open source community, but also aims to stimulate the creativity of the industry and the community, and jointly promote technological progress in this field.
The research work published this time covers several key factors for the success of video generation models: the “art” of refining the data infrastructure and the “way” of large model training scale. The team shared the core process of its data infrastructure and released the highest quality large-scale open source dataset Koala-36M in the field of video generation, providing a solid foundation for model training in academia and the community. At the same time, the Scaling Law in language models was introduced into the field of video generation, systematically revealing the relationship between model size, hyperparameter selection, and training performance, providing scientific guidance for efficient training and performance optimization.
In addition, they actively collaborate with academia to jointly explore the future direction of technological evolution. This time, they shared the recent results of their collaboration with Tsinghua University: a new video generation paradigm called Owl-1. This method uses a universal world model to model the video generation process, and achieves long-video generation with consistent timing through closed-loop reasoning evolution of state-observation-action. It shows a more promising future for video generation technology.
The “art” of refining data infrastructure, the data link behind Koling
In today’s era of large models, the importance of data is self-evident. High-quality large-scale datasets are the basis for training high-performance models. However, the current video generation field lacks high-quality large-scale pre-training data, which has become a bottleneck restricting model development.
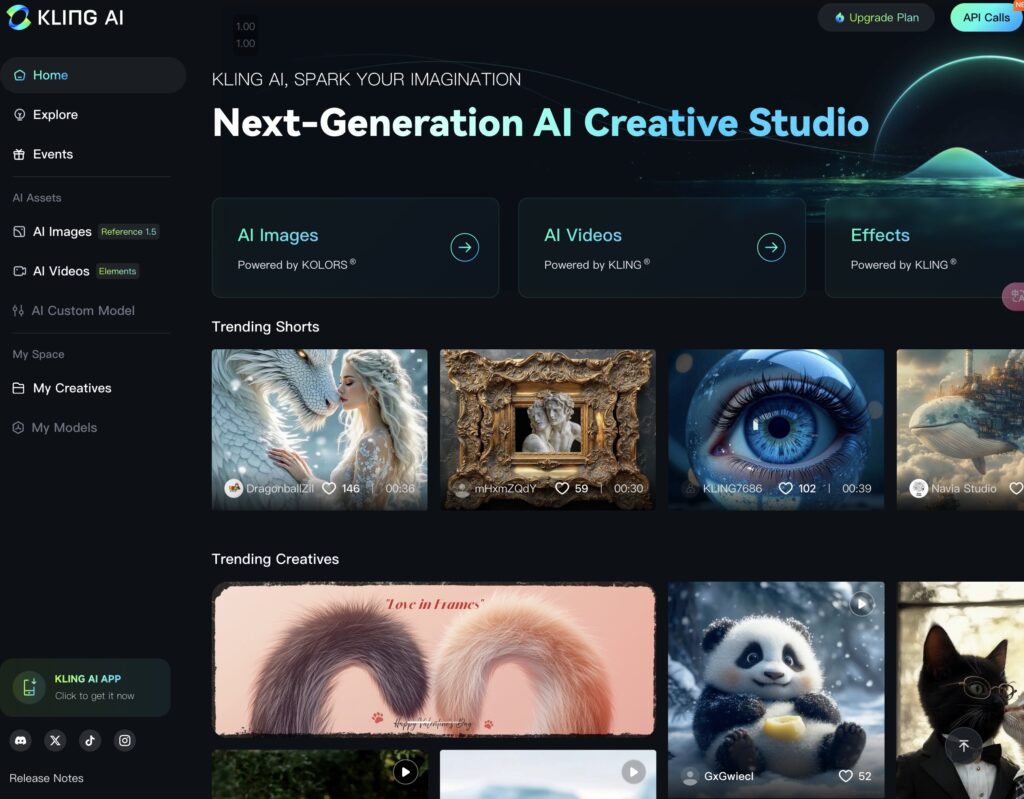
To address this problem, the Kling team has open-sourced Koala-36M, which is currently the highest-quality open-source large-scale video generation dataset. The data processing process behind it is also an important support for Kling’s large models. Compared with the SOTA dataset Panda-70M [1], Koala-36M has made improvements in video slicing, text annotation, data filtering, and quality perception, which has greatly improved the consistency of text-to-video.
As shown below, with the same generative model and number of training steps, the model pre-trained on Koala-36M has higher generative quality and stronger convergence than Panda70M, which fully proves the effectiveness of the dataset and processing pipeline.

The title of the corresponding paper of the open source Koala-36M from Kuaishou is: A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content.
Koala-36M contains 36 million video clips with an average length of 13.75 seconds and a resolution of 720p. The average length of the text captions for the clips is 202 words, which is a significant improvement in quality compared to existing datasets.
Method introduction
As shown in the following renderings, Panda-70M has the problems of insufficient video segmentation, short text descriptions, and the retention of some low-quality videos. Koala-36M makes more detailed and precise improvements in the above aspects.

The starting point of Koala-36M is to provide accurate and detailed conditional control for the video generation model. Through more accurate video segmentation, more detailed text descriptions, and richer conditional introduction, the model perception is more consistent with the video content.
There are currently some key issues to be resolved in the processing of video generation datasets:
- Alignment of text and video semantics: Because video visual signals are more detailed, the corresponding text descriptions need to be rich and detailed. In addition, because the original video data often contains complex transitions, it makes it more difficult to align the semantics of the text.
- Low-quality data screening: Low-quality videos (e.g., poor image quality or excessive special effects) can hinder model training, but data quality assessment and screening are still not very good. At present, most mainstream methods rely on other manually selected quality indicators and heuristic threshold screening, which are not designed for video generation tasks. Therefore, there are cases of missed detection of low-quality data and erroneous deletion of high-quality data.
- Data quality heterogeneity: Even after data screening, different videos still have quality deviations in different dimensions. However, the model cannot perceive these deviations, and simply feeding the model with these heterogeneous data may lead to uncertainty in model learning.
More accurate and faster video cutting
Video slicing is a key step in building a video text dataset. Videos without transitions can better fit the text description, which is beneficial for model learning, thus making the generation results more consistent over time. Currently, video segmentation algorithms generally use PySceneDetect [2], which does not perform well in identifying gradual transitions.
Koala-36M proposes a new segmentation algorithm, Color-Struct SVM (CSS), which calculates the structural distance and color distance between frames and inputs it to an SVM to learn the ability to recognize transitions. For gradual transitions, Koala-36M assumes that the video is relatively stable over time and estimates the Gaussian distribution of changes in past frames. It determines significant changes based on whether the change in the current frame exceeds the 3σ confidence interval. This method enhances the ability to distinguish between gradual changes and fast-moving scenes without increasing the computational burden. Koala-36M further tested the algorithm on 10,000 video clips with annotated transitions to demonstrate the effectiveness of the algorithm in terms of accuracy and running efficiency.


More granular caption algorithm
More detailed video descriptions lead to better video text consistency. To obtain more detailed text descriptions, Koala-36M uses a structured text annotation system, where a text description is broken down into the following six parts:
- Subject description
- Subject movement
- Subject environment
- Visual language: composition, style, lighting, etc.
- Camera language: camera movement, perspective, focal length, etc.
- Overall description
Similar to existing work, Koala-36M first generates preliminary text annotations through GPT-4V [3], fine-tunes the text annotation network based on LLaVA [4], and labels the remaining data. A mixed image and video training method was used during training to alleviate the problem of insufficient diversity of video data. The final text description length distribution of Koala-36M is as follows.

A new data filtering process
The quality of the original video data is uneven, and it is necessary to screen out low-quality data and retain high-quality data. As shown in the blue box in the figure below, the traditional data screening method measures the quality of the video through multiple sub-metrics and manually sets thresholds to screen the video. Since the video quality is a joint distribution of all sub-metrics, and the sub-metrics are not completely orthogonal, there should be implicit constraints between the set thresholds. However, the existing method ignores the joint distribution of the sub-metrics, resulting in inaccurate threshold settings. At the same time, because multiple thresholds need to be set, the cumulative effect of inaccurate thresholds causes large deviations in the screening process, ultimately leading to the missed detection of low-quality data and the erroneous deletion of high-quality data.

To solve this problem, Koala-36M proposes the Training Suitability Assessment Network (TSA), which is used to model the joint distribution of multiple sub-metrics. The network takes videos and sub-metrics as inputs and outputs a single value, the “Video Training Suitability Score (VTSS)”, as the sole indicator for screening data, which directly reflects whether the video is suitable for training purposes. Specifically, Koala-36M constructs a new video quality evaluation system that considers three dimensions: dynamic quality, static quality, and video naturalness. Users are invited to evaluate and give a unique score, which is normalized to reflect whether the video is suitable as training data for video generation models.

The Multimodal Input Video Assessment Network (TSA) is used to fit the user’s score. As shown in the figure above, the network is divided into three branches. The dynamic branch is based on the 3D Swin Transformer, the static branch is based on the ConvNext network, and various data labels in the traditional data filtering strategy are also retained. They are passed to the network model as additional information through the new branches, and the features of different branches are fused through the Weighted Cross Gate Block (WCGB). As shown in the figure below, the filtering process of Koala-36M can greatly reduce the situation of low-quality data being missed and high-quality data being mistakenly deleted.


Enhancing the model’s perception of heterogeneous data
In the existing data process, the labels of data are simply used for data filtering. However, the quality of the filtered data varies, making it difficult for the model to distinguish between high-quality and low-quality data. To solve this problem, Koala-36M proposes a more refined model perception method that injects quality labels of different videos into the generative model during training, thereby improving the consistency between conditions and video content.

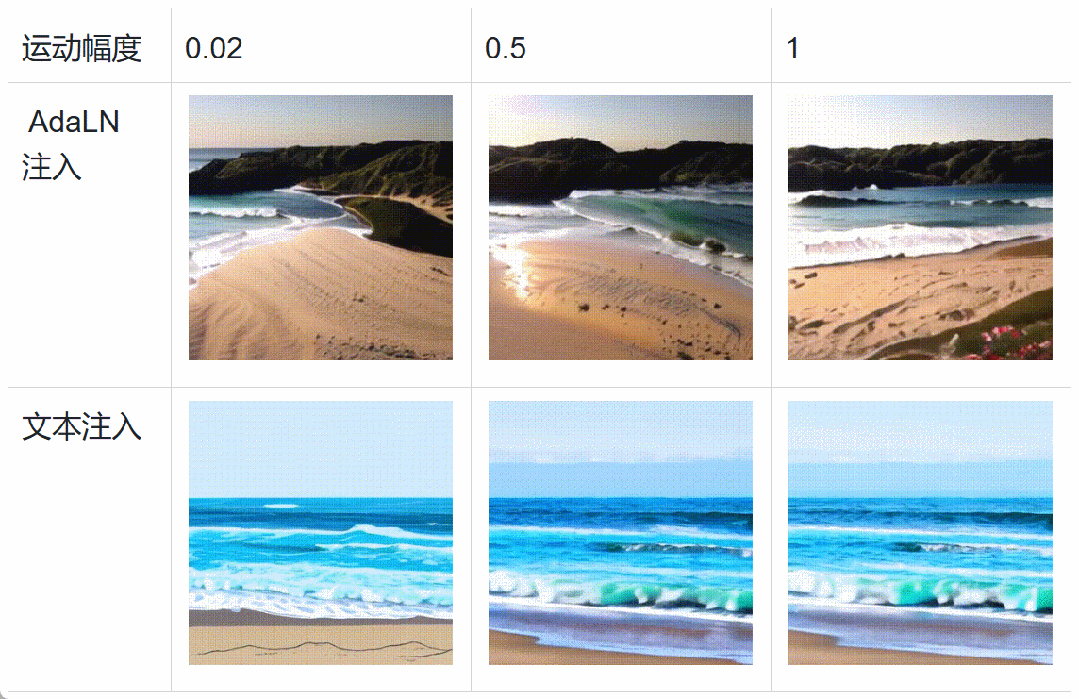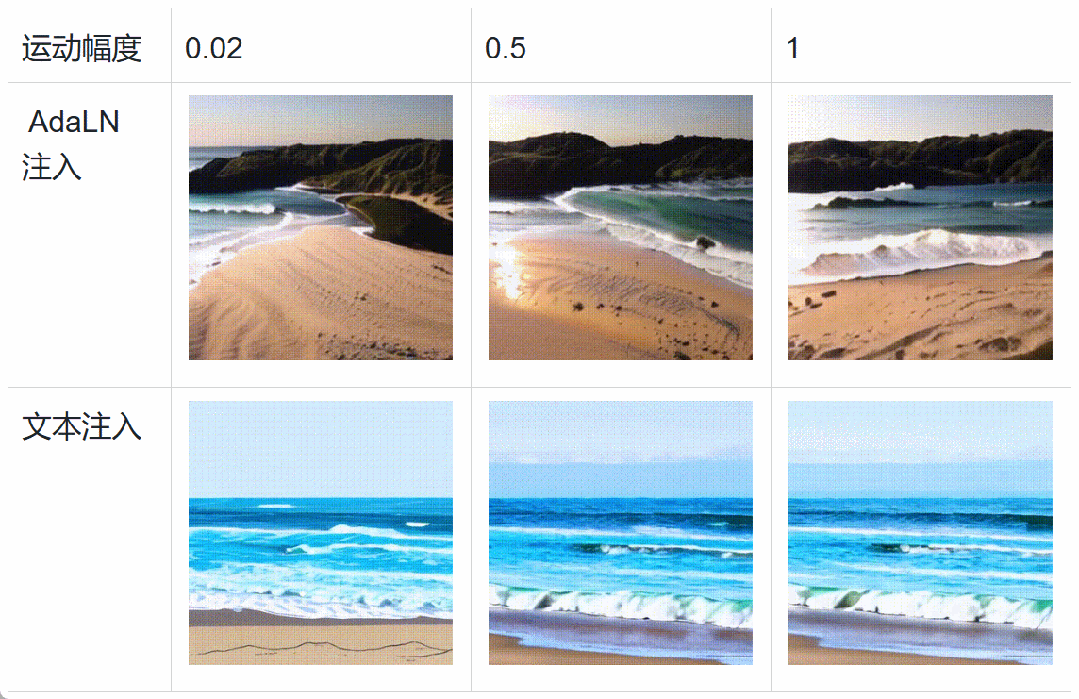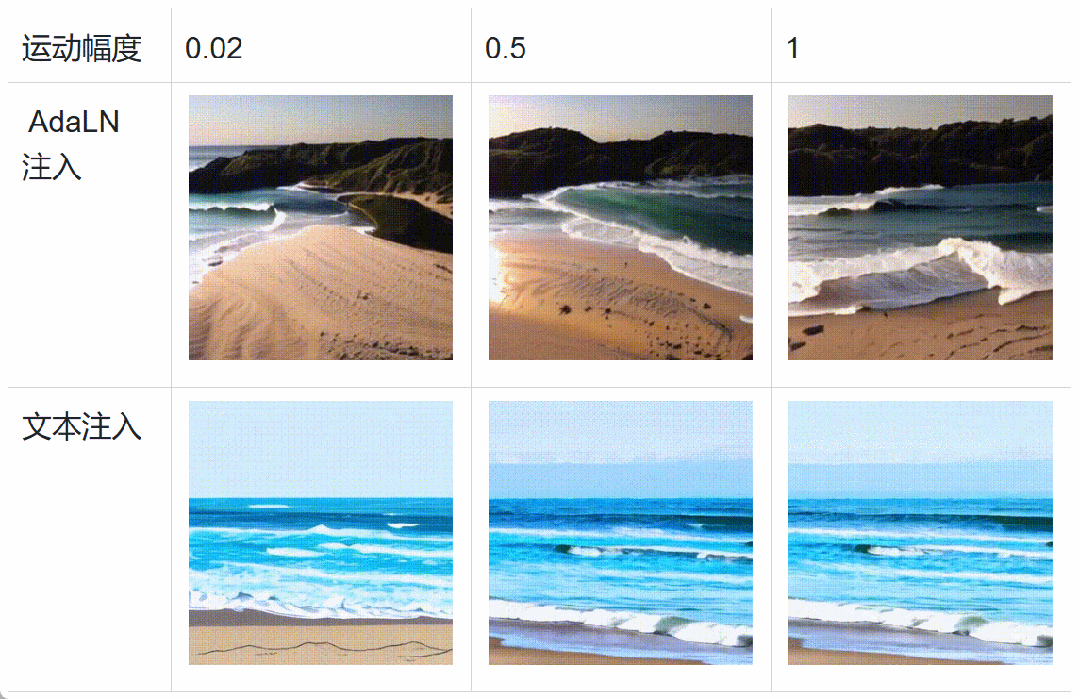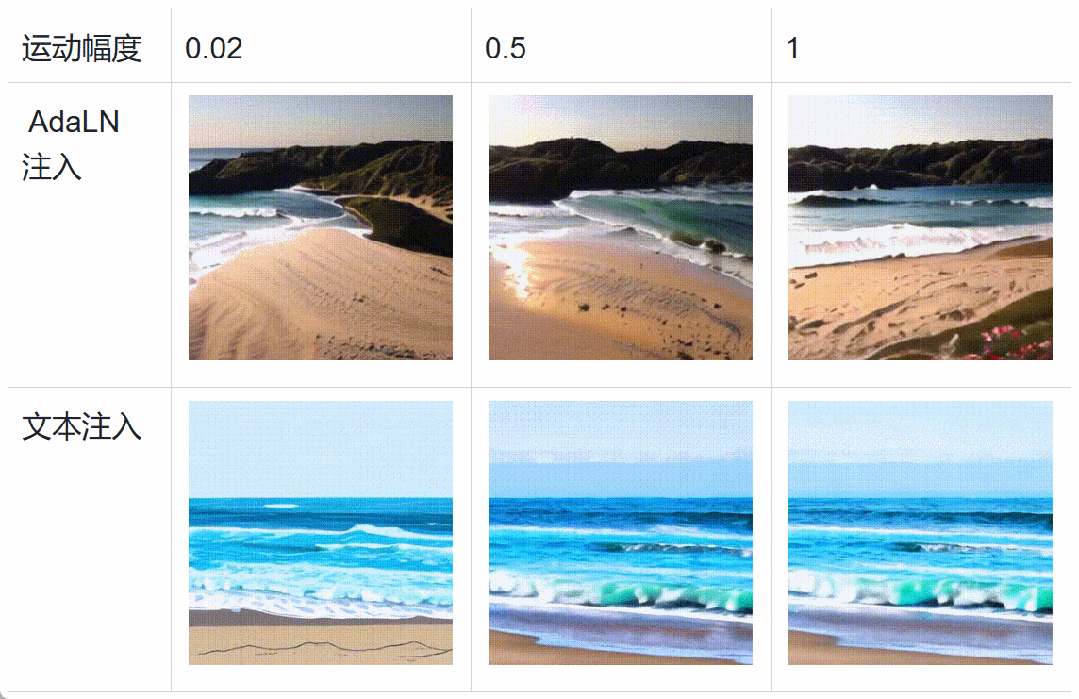
Specifically, during the training of the diffusion model, data such as motion scores, aesthetics scores, and clarity scores are added to the Transformer through adaptive layer normalization (AdaLN). This conditional addition does not increase the computational load of the diffusion model, but rather enhances the model’s perception of heterogeneous data and accelerates model convergence. During the inference stage, different feature scores can be set to finely control video generation. In addition, the figure below shows that the AdaLN-based injection method has finer motion amplitude control and stronger style decoupling ability than the text encoder-based injection method.
Experimental comparison
Koala-36M pretrain the same video generation model on different datasets, control the same number of training steps, and measure the quality of video generation to further verify the effectiveness of the data processing pipeline and training strategies. The experiment is divided into the following six groups:
- Panda-70M: baseline
- Koala-w/o TSA: all 48M data after video segmentation and text annotation without data screening
- Koala-37M-manual: manually filtered data from 48M using multiple thresholds
- Koala-36M: filtered data set from 48M using VTSS
- Koala-w/o TSA (condition): unscreened 48M data with metrics condition injection
- Koala-36M (condition): Koala-36M data with metrics condition injection
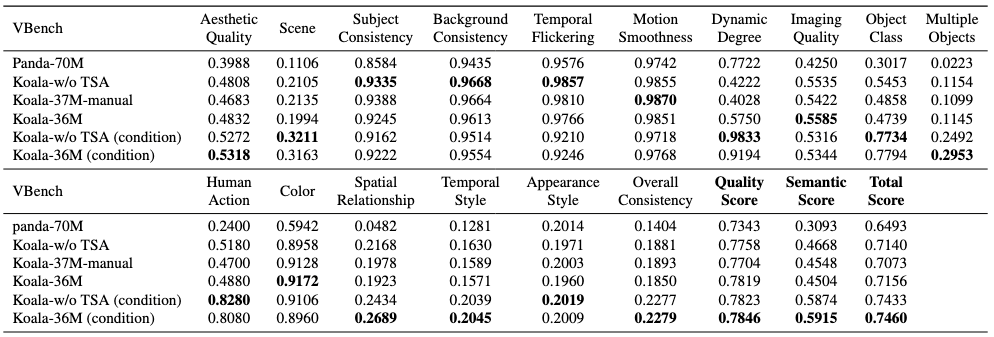
Comparing the training results of Koala-w/o TSA and Koala-36M, and Koala-w/o TSA (condition) and Koala-36M-condition, the latter results are better than the former, indicating that filtering low-quality data can prevent the model from learning a biased distribution from low-quality data.
In addition, the training results of Koala-37M-manual and Koala-36M show that the filtering method based on a single VTSS can obtain better filtering results than manually setting thresholds. Comparing the training results of Koala-36M and Koala-36M (condition), when the metrics condition is injected, the video quality of the generated model is significantly improved, indicating that using metrics to guide model training helps the model implicitly perceive the importance of different data.
Koala-36M Summary
Koala-36M is a large-scale high-quality video text dataset with precise video segmentation, detailed text descriptions and higher-quality video content. This dataset is currently the only video dataset that has both a large number of videos (over 10 million) and high-quality fine-grained text descriptions (average caption length over 200 words), which greatly improves the quality of large-scale video datasets. In addition, in order to further improve the consistency between fine-grained conditions and video content, Koala-36M proposes a complete data processing pipeline, including a better video slicing method, a structured text annotation system, an effective data filtering method, and heterogeneous data awareness.
The “Law” of Large Model Training Scale Video Generation Scaling Law
Video generation is quickly becoming a core focus of the artificial intelligence field, with huge potential for applications ranging from entertainment content creation to advertising production, virtual reality, and online education. However, unlike static image generation, video generation tasks require modeling both the visual structure and dynamic changes in the temporal dimension. They also need to deal with a complex high-dimensional solution space to accurately simulate real-world dynamic scenes. This complexity not only significantly increases the demand for data and computing power, but also makes trial and error costly. Therefore, how to achieve optimal performance within a given data and computing budget has become a key challenge that needs to be urgently addressed in the field of video generation.
The current representative video generation model Movie Gen has a parameter scale of 30 billion, far exceeding the early Video DiT (about 700 million parameters). In this context, the importance of Scaling Law is becoming increasingly prominent. Although Scaling Law has been used to predict performance in language models, its existence and accurate derivation in visual generation models has not been fully explored.
In response to this problem, in the paper “Towards Precise Scaling Laws for Video Diffusion Transformers,” the Fast Research team proposes a more precise Scaling Law modeling method for visual generative models (Video DiT).
This paper is the first to precisely model batch size and learning rate, providing guidance for optimal hyperparameter selection for any model size and computational budget, and accurately predicting the validation loss under the optimal hyperparameter configuration. In addition, the paper further establishes an accurate relationship between the optimal model size and the computational budget. Experiments show that compared with the traditional Scaling Law method, the derivation method proposed in this work can reduce the inference cost by 40.1% while maintaining comparable performance under a computational budget of 1e10 TFlops. This result provides a new direction for efficient optimization in the field of video generation and important insights for the industry to develop large-scale video generation models.
Background
In recent years, research on large language models (LLMs) has revealed a power law relationship between model performance, model size, and computational budget, which is known as the Scaling Law. By experimenting with small-scale models, researchers can effectively predict the performance of large-scale models, thereby achieving efficient model optimization under resource constraints. Although the Scaling Law has achieved remarkable results in the field of language models, and preliminary research has also been conducted on the Scaling Law of Image DiT, the unique complexity of video generation has left this field largely unexplored, posing a significant obstacle to the development of larger-scale video generation models.
Technical difficulties: Video DiT models are highly sensitive to hyperparameters
With the development of Video Diffusion Transformers (Video DiT), significant progress has been made in terms of the quality and diversity of generated videos. This paper attempts to extend the Scaling Law method in the field of language models to Video DiT. However, it is found that the performance of Video DiT models is highly sensitive to hyperparameters such as batch size and training steps. Empirical parameter selection often introduces large uncertainties, which significantly affects the model validation loss (as shown in Figure 1). Therefore, it is particularly important to construct an accurate Scaling Law for Video DiT and optimize the hyperparameter configuration.
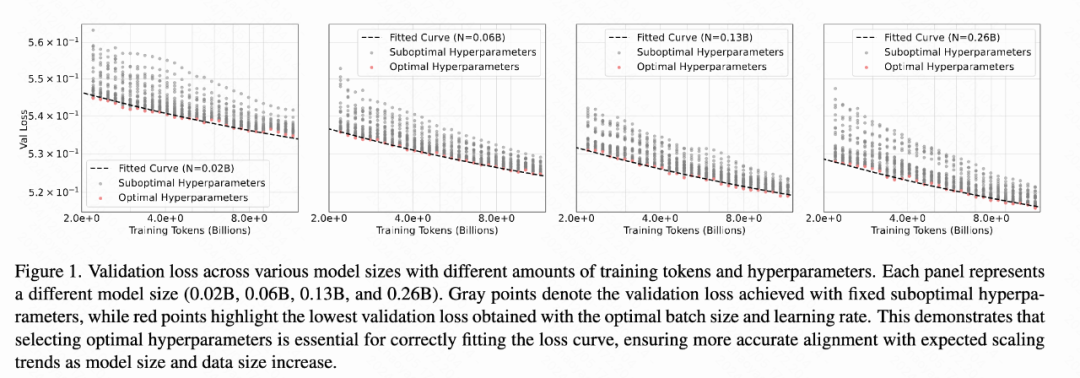
Limitations in classical Scaling Law research
In the study of Scaling Laws for language models, the selection of optimal hyperparameters is often ignored or controversial. Early studies often relied on heuristic methods, lacking a systematic theoretical basis to guide hyperparameter selection. Existing Scaling Law studies still have deficiencies in the fine-grained exploration of the relationship between model size and hyperparameters, which is crucial for optimizing computing resources and improving fitting accuracy. The problems with existing Scaling Laws include
- OpenAI’s Scaling Law: OpenAI’s research suggests that smaller batch sizes are more computationally efficient, but require more update steps to converge. However, the experimental results in this paper show that using smaller batch sizes and increasing the number of update steps cannot achieve the lowest validation loss with the same computational budget. This shows that in the video generation task, a smaller batch size is not necessarily the best choice to improve computational efficiency.
- Chinchilla’s Scaling Law: Chinchilla’s research established a relationship between the validation loss and the model parameter N and the amount of training data D, but the fitting results of the validation loss deviated from the IsoFLOPs curve in the prediction of the optimal parameter quantity. The article believes that the deviation may be due to a fixed suboptimal hyperparameter configuration, which leads to an inaccurate prediction of the model size.
- DeepSeek’s Scaling Law. DeepSeek’s research shows that, given a specific computational budget, the optimal batch size and learning rate combination that minimizes the validation loss can be found. However, this method only selects the optimal hyperparameters corresponding to the optimal model parameters, and fails to fully consider the interaction between hyperparameters and model size and training data volume, which limits the applicability of the method in a wider range of scenarios.
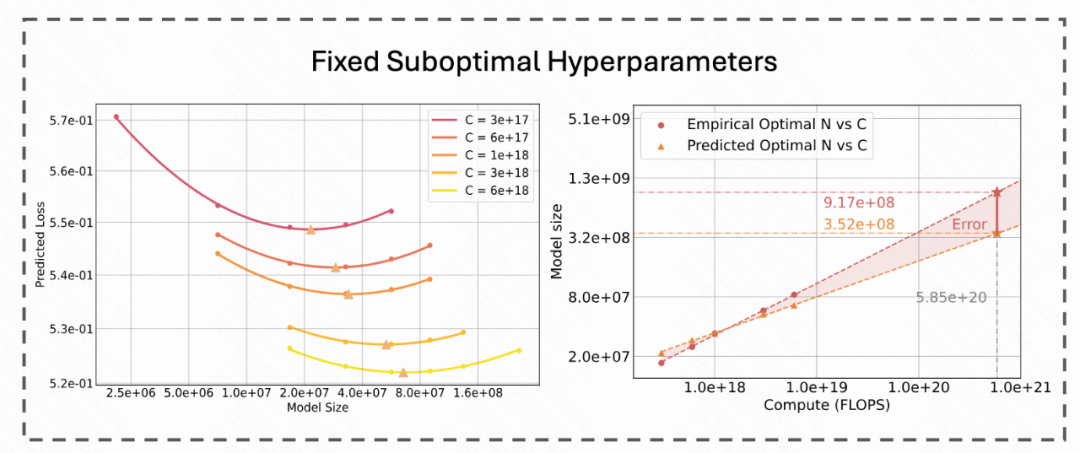
Through analysis and reflection on these classic studies, the authors found that optimizing hyperparameter configuration is crucial for constructing a Scaling Law suitable for Video DiT. Therefore, this paper will discuss in depth the role of hyperparameters in optimizing model performance, and predict hyperparameters given the model size and amount of training data, in order to provide a more accurate theoretical basis and practical guidance for training large-scale models.
Predicting optimal hyperparameters
Through theoretical derivation and experimental verification, the researchers have constructed a prediction formula for the optimal learning rate and batch size, and achieved accurate prediction of large-scale models through extrapolation.
Trade-offs in learning rate selection. The choice of learning rate needs to balance the benefit of each step with the number of effective update steps (the number of steps where the validation loss decreases) to maximize the overall optimization benefit. Based on theoretical derivation, this paper proposes an optimal learning rate formula, where the parameter values are as shown in the table:


Experimental results show that there is a clear nonlinear relationship between the learning rate and the model size and the amount of training data. The fitting curve based on the formula can accurately predict the optimal learning rate for models of different sizes.
Trade-off of training batch size. The choice of training batch size needs to balance the gradient noise per step with the total number of update steps. To this end, this paper theoretically proposes an optimal batch size formula, and the parameter values are shown in the table.
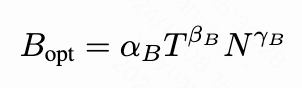

Experimental results show that the batch size also has a significant dependence on the model size and the amount of training data. The accuracy of the fitted curve is consistent across different model sizes.
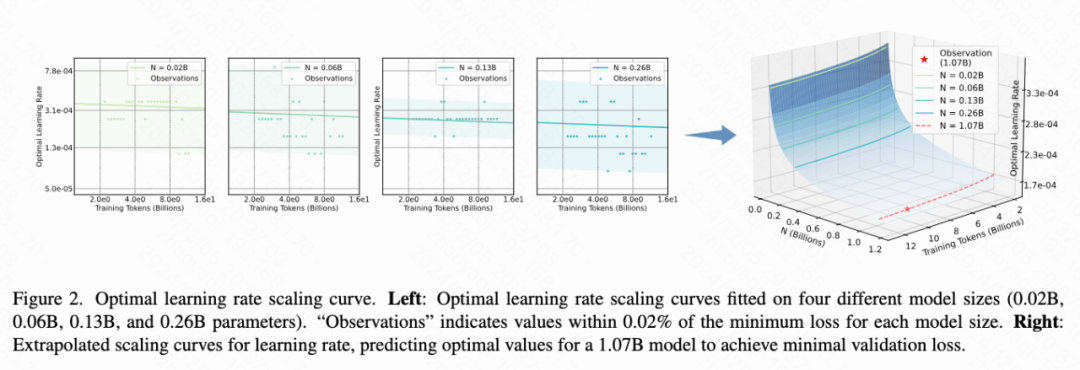
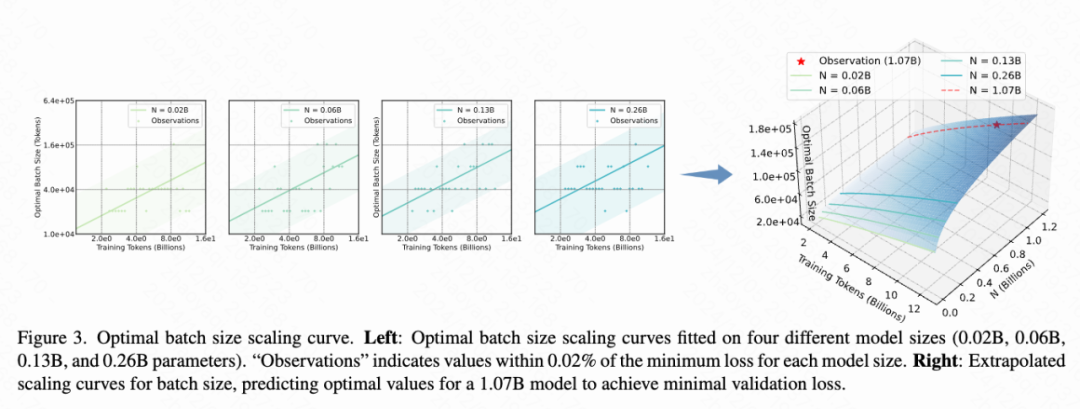
Extrapolation verification: To verify the applicability of the formula, this work extends the model parameters to 1B and performs optimal hyperparameter prediction on training data sets of 4B and 10B respectively. The experimental results show that the hyperparameters predicted based on the formula can effectively reduce the validation loss, and their accuracy is close to the true value (as shown in Figure 4).

More accurate Scaling Law: Explore the performance boundaries of the video DiT model
Based on the prediction of the above optimal hyperparameters, the researchers propose a more accurate Scaling Law for Video DiT. From the perspective of balancing model size, training data volume and computing budget, it can not only predict the optimal model size for a given computing budget, but also provide more accurate performance predictions for models of different sizes.
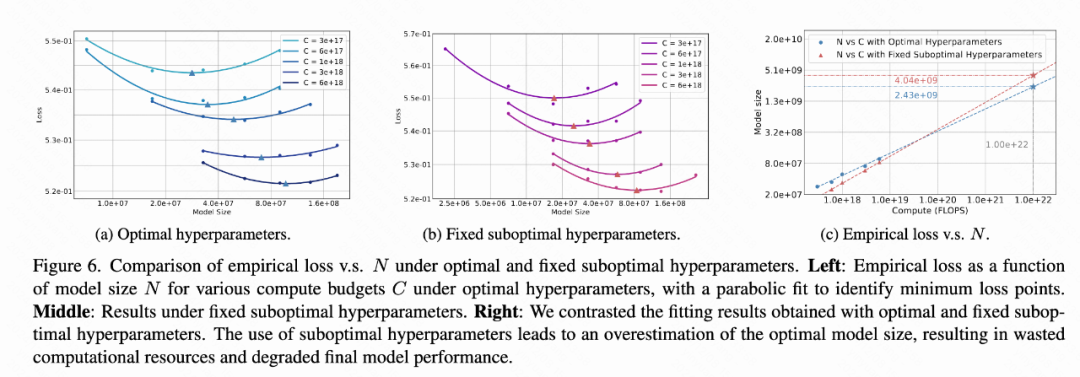
More efficient empirical optimal model parameter prediction. The research compares the prediction deviation of empirical optimal model parameters (IsoFLOPs curve) when using optimal and suboptimal hyperparameter configurations under different computational budgets such as [3e17, 6e17, 1e18, 3e18, 6e18] (Figure 6). The research found that
For the same computational budget (10^10 TFLOPs), the empirical optimal model parameters using the optimal hyperparameters can reduce the number of parameters by about 39.9% compared to the non-optimal hyperparameters (Figure 6c), and the inference cost is reduced by 40.1%. This brings huge benefits in practical application deployment.
Based on this, this paper gives an empirical prediction formula for the empirical optimal model parameters
A more accurate validation loss fitting formula. The research further analyzes the change of the model validation loss with the number of training tokens T and the model size N. The paper is based on the assumption that
- when, n\rightarrow\infty the minimum loss achieved depends on the training data entropy and noise. Similarly, when T\rightarrow\infty , it depends on the model size.
- When the computational budget tends to infinity, the loss tends to the training data entropy L♾️
Based on the above assumptions, the following validation loss formula is proposed:

Fitting results
The researcher obtains the fitting results under the premise of optimal hyperparameters as shown in the table. Extrapolation and verification are carried out in the scenarios of 1.07B model + 10B training tokens and 0.72B model + 140B training tokens, and the verification loss errors are 0.03% and 0.15% (Figure 5), respectively, which proves the high fitting accuracy of the formula.
In addition, the researchers imposed a computational constraint on L (N, T) to obtain the predicted optimal model parameters (Predicted Optimal Model Size) and the empirical optimal model parameters (Empirical Optimal Model Size):
Under the setting of optimal hyperparameters, the fitting results of the two are highly consistent (the exponential term deviation is 3.57%), which further proves the high accuracy of L (N, T) fitting.
Using a fixed non-optimal hyperparameter configuration, there is a significant deviation in the fitting results (the exponential term deviates by 30.26%), which is consistent with the results observed in Chinchilla’s Scaling Law method 3. This paper believes that the reason for this significant deviation is that the fitting has a non-optimal hyperparameter configuration as shown in Figure 1. The gray experimental points reduce the fitting degree of L (N,T).


Summary
This paper provides an in-depth discussion of the Scaling Law for Video DiT and proposes a new framework to optimize hyperparameter selection, model size and training performance, providing guidance for efficient training. Specifically:
- Scaling Law for Hyperparameters. This paper proposes a new scaling law for determining the optimal hyperparameters for Video DiT through theoretical analysis and experimental verification. The optimal hyperparameters mainly depend on the model size N and the amount of training data D, and an accurate fitting formula is given.
- Scaling Law for Optimal Model Size. Based on the optimal hyperparameters, the method can more accurately predict the empirical optimal model size. When using the same computing resources as Movie Gen, this method reduces the model size by 39.9% while maintaining similar performance.
- Scaling Law for Performance. Under the optimal hyperparameter configuration, this paper derives a general formula that can accurately predict the validation loss for different model sizes and computing budgets. The study shows that when the model size is close to the optimal value, the validation loss tends to stabilize when the computational budget is fixed, thereby significantly reducing the inference cost when the performance is comparable (predictable). In addition, the results of this paper provide an accurate extrapolation of the relationship between model size and computational budget. In contrast, using fixed suboptimal hyperparameters can lead to a significant increase in prediction errors.
Video generation is the future trend Universal world model
Currently, visual generation models have made significant progress in image generation and video generation. However, these models still face some challenges, especially when generating long videos, where maintaining temporal consistency and logical plausibility is a difficult problem. Traditional generative models often rely on large amounts of data and complex network structures, but these problems are still difficult to fully solve. To address these challenges, Tsinghua University and Kuaishou Technology have jointly proposed the Omni World Model (OWM). This model evolves through closed-loop reasoning of state-observation-action, achieving long video generation with consistent timing. Let’s take a closer look at the core technology and advantages of Owl-1.
- Closed-loop system of state-observation-action 🔄
- State variable: captures the current state and historical information of the world, and can be decoded into corresponding videos by the video generation model.
- Observation variable: direct observation of the current state of the world, i.e., the video frames seen.
- Action variables: describe the law of change of the world state over time, are presented in text form, and drive the evolution of the world.
These three components together form a closed-loop evolutionary system that interacts and influences each other, jointly driving the continuous evolution of the world and the generation of videos.
- Improved temporal consistency and logical plausibility 🕒
The universal world model can directly capture and simulate the spatio-temporal evolution of the three-dimensional world, thereby improving the temporal consistency and logical rationality of generated videos. This means that the generated videos not only look natural, but also have more coherent content, avoiding monotony or repetition.
- Rich content diversity 🎨
By predicting and utilizing evolutionary action variables, Owl-1 can enrich the content diversity of generated videos. This makes the generated videos more lively and interesting, and better reflects the laws of change in the real world.
Paper title: Owl-1: Omni World Model for Consistent Long Video Generation Project homepage: https://github.com/huang-yh/Owl
paper: https://arxiv.org/abs/2412.09600

Method introduction
The goal of Owl-1 is to construct a consistent long video generation model. The core of this model is to use an Omni World Model to model the video generation task. Why use an Omni World Model? Because video data is essentially an observation of the evolution of the surrounding world, a projection of 4D space-time into 3D. A universal world model can directly capture and simulate the spatio-temporal evolution of the 3D world, so modeling the video generation task from the perspective of a world model is a more effective and essential approach. On the one hand, the consistency of 4D space-time can improve the temporal consistency of the generated video; in addition, explicit modeling of the evolution of the world can also improve the diversity and logic of the generated video content, avoiding monotonous or repetitive content.

Modeling a generic world model
A generic world model has three core components: hidden space state variables, explicit observation variables, and evolution action variables. These three components each play a different role: hidden space state variables capture the current state and historical information of the world, and can be decoded into corresponding videos by the video generation model. Explicit observation variables are direct observations of the current world state, i.e., the video frames seen. The evolution action variable describes the law of change of the world state over time, which drives the evolution of the world and is presented in text form.
The hidden space state variable is the core of Owl-1. It not only focuses on the pixel information of the video itself, but also delves into the world behind the video. By capturing and representing the dynamic changes of this world, it more accurately simulates the evolution of the world and generates longer videos that are more coherent and consistent.
Evolutionary action variables are the key factors driving the evolution of the world. They exist in the form of text and describe the dynamic change process between the world at different moments. By predicting and utilizing these evolutionary action variables, Owl-1 can enrich the diversity of the generated video content and ensure the consistency and coherence of the video.
These three components of Owl-1 together form a closed-loop evolutionary system. The three components interact and influence each other, jointly driving the continuous evolution of the world and the generation of the video.

Model structure
Owl-1 makes full use of a pre-trained large multimodal model (LMM) and a video diffusion model (VDM). The LMM is the core component of the general world model, which directly models the evolution of the state-observation-action triplet. The video diffusion model is responsible for decoding the hidden state variables into short video clips, i.e., explicit observation variables, and then inputting them into the LMM for subsequent inference. Through the collaborative work of these two models, Owl-1 realizes the modeling of a closed-loop general world model.
Customized multi-stage training process
Owl-1 uses a multi-stage training process. The first is the alignment pre-training stage, where a large-scale short video dataset is used to train the multimodal large model to output hidden space state variables that are aligned with the video diffusion model. This stage only trains the multimodal large model and can provide a good initialization for the subsequent training process. Then comes the generative pre-training stage, which mainly strengthens the ability of the video diffusion model to generate explicit video observations based on the hidden state variables. Therefore, this paper jointly trains the multimodal large model and the video diffusion model. Finally, there is the world model training stage. Since there is no video dataset that embodies the concept of a world model, this paper uses two dense video captioning datasets, Vript and ActivityNet, to integrate the hidden state variables, explicit observation variables, and evolved action variables to form a complete general world model.
Results
Here we show the results of Owl-1 generating videos of different lengths, including 2 seconds, 8 seconds and 24 seconds. The 2-second generated video uses the text prompt from VBench, and the 8-second and 24-second videos use the text prompts from the WebVid or Vript datasets.

Based on the given initial frame and text description, Owl-1 can generate videos with large changes in posture and scene, and the generated videos can reflect the changing laws of objects and scenes in the real world. This shows that Owl-1 can decode explicit video observations from hidden space state variables very well.

For the generation of multiple short videos (~8 seconds) of the same scene, Owl-1 can achieve seamless transitions between videos and generate videos with high consistency. This verifies the ability of the hidden state variables to maintain the consistency of the video content.

For the generation of multiple long videos across scenes (~24 seconds), Owl-1 shows superior performance in scene transitions, motion capture, and detail rendering. The generated videos are not only coherent and smooth, but also rich in detail and show a certain logic in the development of video content. This verifies the important role of the evolved action variables in the development of video content, and initially demonstrates the advantages of the video generation paradigm based on the world model.
Quantitative results
In this paper, we tested Owl-1’s ability to generate short videos and long videos on the VBench-I2V and VBench-Long benchmarks, respectively.

The table above shows Owl-1’s experimental results on VBench-I2V. The results show that Owl-1 is comparable to other models in most metrics, but still lags behind in dynamics and aesthetics, which may be related to the dynamics and aesthetics of the video data used for training.

The table above shows the experimental results of Owl-1 on VBench-Long. Owl-1 achieved comparable performance with open source video generation methods, with the best performance in consistency-related metrics. This shows that Owl-1 outperforms existing methods in maintaining the temporal consistency of long videos.
Summary
The Kuaishous “Kling Large language Model” team has always focused on the cutting-edge exploration and continuous innovation of video generation technology. Through the optimization of model architecture, the improvement of data quality, and breakthroughs in algorithm paradigms, the team is committed to promoting the continuous progress of video generation technology. Looking to the future, as these technologies continue to improve and mature, video generation will become more efficient and high-quality, bringing users richer and more diverse creative expression and usage experiences.